Das Data Warehouse ist aufgebaut, die Daten fließen, die Datenbank füllt sich mit betriebsrelevanten Informationen. Der nächste Schritt ist natürlich die Analyse der Daten. Doch die Zeiten des Excel-gestützten, mühseligen rumkopieren oder der manuellen Aufarbeitung und Erstellung von Powerpoint-Grafiken sind vorbei.
Die Zukunft gehört der automatischen, dynamischen Erstellung von attraktiven und interaktiven Datenvisualisierungen mittels performanter höheren Programmiersprachen.
Die Tools
Es gibt natürlich eine ganze Palette an Programmiersprachen und Visualisierungs-plugins. Hier wählen wir die Sprache python mit der plotly Grafikbibliothek. Zur Datenbankverbindung das Package SQLAlchemy, für die Aufbereitung pandas. Pandas kann natürlich auch aus den verschiedensten anderen Quellen, wie .csv und .json-Dateien oder direkt aus python dictionaries, lesen.
Wieso genau diese Kombination? Verfügbarkeit auf allen Plattformen, einfache Syntax und schnelles Prototyping!
Um den Komfort weiter zu steigern wird zum Setup miniconda verwendet, als „Entwicklungsumgebung“ Jupyter-Lab.
Da es zur Installation all dieser Tools über miniconda ausreichend Tutorials gibt, wird hier nicht weiter darauf eingegangen.
Plotly Test
Nach dem Starten von Jupyter wählt man die Erstellung eines python3-Notebooks. Als Erstes importieren wir das graph_objects Modul aus dem plotly Package und testen, ob die Darstellung funktioniert:
import plotly.graph_objects as go fig = go.Figure(data=go.Bar(y=[2, 3, 1])) fig.show()

Funktioniert einwandfrei. Als Nächstes stellen wir die Verbindung zur Datenbank her.
Verbindung zur Datenbank
Dazu importieren wir erst die nötigen Module und Funktionen aus SQLAlchemy. create_engine ist für die Anbindung an die Datenbank API und die Übersetzung der verschiedenen Datenbank-Dialekte zuständig. sessionmaker liefert ein Session Objekt, welches die Kommunikation mit der Datenbank abwickelt und in der Datenbankobjekte temporär gespeichert sind. Mehr Information gibt es unter https://www.sqlalchemy.org/.
from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker
Anschließend erstellen wir die Engine und binden sie an ein Session Objekt. Der Connection String ist natürlich von der jeweiligen Datenbank abhängig. Hier arbeiten wir mit Microsoft SQL Server. Aus Sicherheitsgründen wird der genaue String hier über eine Environment Variable eingelesen. URLs für die verschiedenen Datenbanken findet man unter
https://docs.sqlalchemy.org/en/14/core/engines.html#database-urls.
import os
from dotenv import load_dotenv
load_dotenv(".env")
engine = create_engine(os.getenv("SQLALCHEMY_DATABASE_URI"))
Session = sessionmaker(bind=engine)
In dieser Datenbank finden sich österreichische COVID-19 Daten entnommen aus dem Open-Data Portal https://www.data.gv.at/covid-19/. Sehen wir uns die Impfdaten an. Dazu nutzen wir pandas Dataframes in Verbindung mit einer neuen Instanz des Session Objektes.
import pandas as pd
session = Session()
austria_df = pd.read_sql_table("Oesterreich", con=session.connection(),,schema="dbo")
impfung_demo_df = pd.read_sql_table("ImpfungDemografie", con=session.connection(), schema="dbo")
print(impfung_demo_df)
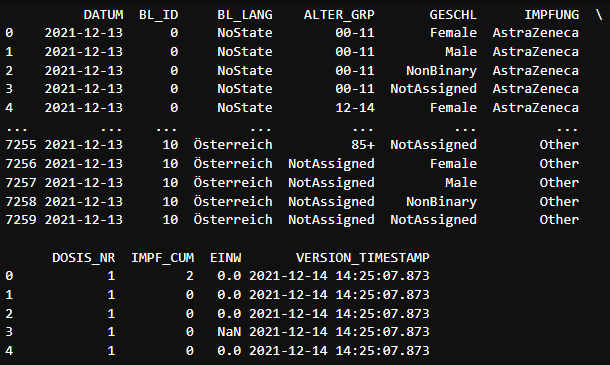
Die Verbindung funktioniert, und wir haben auch schon Daten zur Visualisierung! Dabei haben wir einen guten Mix aus Zeitdaten, numerischen Werten und Gruppen wie Bundeslandnamen oder Geschlecht.
Aufbereitung mit pandas
Als Erstes soll man überlegen, welche Informationen man darstellen will und wie viel davon in einer Grafik. Will man alle Bundesländer in einer Grafik vergleichbar machen? Dann kann man schwer nach Geschlechter oder Altersgruppen aufschlüsseln ohne durch die Informationsüberladung die Grafik unbrauchbar zu machen.
Dann lieber jedes Bundesland einzeln und entweder nach Geschlecht oder Altersgruppe aufschlüsseln.
Die nächste Überlegung ist: Welchen Wert wollen wir darstellen? Nur die Anzahl an Impfdosen eines bestimmten Impfstoffes? Alle Dosen aller Impfstoffe summiert? “Das klingt unglaublich aufwendig!”, denkt man da leicht. Allerdings mit python und pandas kein Problem.
Wir entscheiden uns hier für die Darstellung von ganz Österreich und wählen den Biontech Impfstoff und die 3. Dosis. pandas macht uns die Filterung dabei ganz leicht.
impf_austria_df = impfung_demo_df[(impfung_demo_df["BL_ID"] == 10) & (impfung_demo_df["IMPFUNG"] ==␣ ,→"BioNTechPfizer") & (impfung_demo_df["DOSIS_NR"] == 3)].copy() print(impf_austria_df)
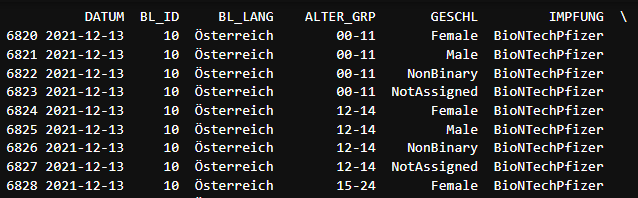
Das sieht ja schon sehr gut aus! Als Nächstes wollen wir Dataframes zu verschiedenen Gruppierungen wie Geschlecht oder Altersgruppen. Hier muss man zusätzlich die Zahlenwerte aggreggieren. Das machen wir mit der sum() Funktion.
impf_alter_df = impf_austria_df.groupby(["ALTER_GRP"], as_index=False).sum() print(impf_alter_df)

Hoppala, da hat es uns natürlich alle Zahlenwerte addiert, auch die Dosisnummer und Bundesland ID. Das kann uns aber egal sein. Bei 2-dimensionalen Grafiken denken wir immer in Form einer x-Achse und y-Achse. Die x-Achse ist hier die Altersgruppe ALTER_GRP, y-Achse sind die kumulierten Impfungen IMPF_CUM. Also haben wir alles, was wir brauchen.
Datenvisualisierung mit plotly
Nachdem die Datenaufbereitung abgeschlossen ist, kommen wir nun endlich zur Visualisierung. Dabei ist die erste Überlegung: “Welche Art von Grafik?”. plotly bietet sehr viele Grafiken. Man kann diese unter https://plotly.com/python/ einsehen.
Welche Grafik geeignet ist, hängt natürlich von den Daten ab. Ist in unseren Daten eine Veränderung über Zeit zu beobachten? Nein, wohl nicht. Es sind Werte abhängig von diskreten Gruppen, auch Kategorien genannt. Da wäre doch ein Balkendiagramm am Schönsten. Erstellen wir eines.
go.Figure liefert dabei die “Umgebung” für eine Grafik, also Layout und die Zeichenfläche. go.Bar definiert den genauen Grafiktyp und wird an das data-Attribut übergeben.
Dann muss man nur noch die x- und y-Achsen definieren. Es werden Listen akzeptiert. Dabei wird jede Stelle der x-Liste auf die jeweilige Stelle der y-Liste abgebildet. Sie müssen also die gleiche Länge haben. Damit die Altersgruppen nicht als Datum interpretiert werden, definieren wir den Typ der x-Achse als Kategorie.
alter_bar_graph = go.Figure(data=go.Bar(x=impf_alter_df["ALTER_GRP"], y=impf_alter_df["IMPF_CUM"]), layout=dict(xaxis=dict(type="category")))
Und wie wär’s noch mit einem Titel?
alter_bar_graph.update_layout(title="Impfungen nach Altersgruppen, ganz Österreich") alter_bar_graph.show()
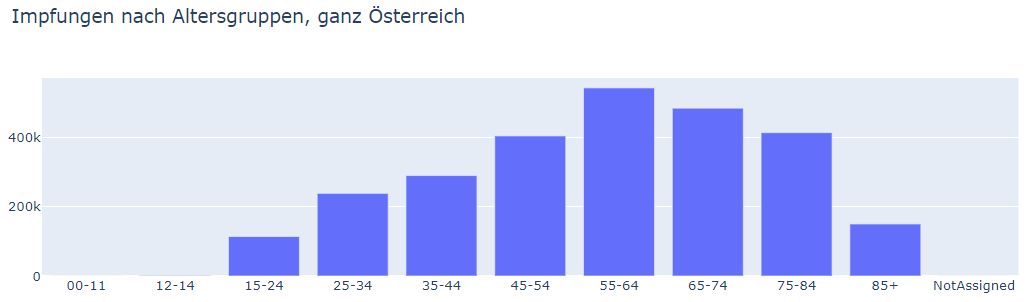
Fertig ist die interaktive Grafik. Es kann frei gestyled werden; Farben, Hintergrund, Größe und vieles mehr sind ganz frei konfigurierbar. Die Demonstration würde allerdings den Umfang dieses Artikels sprengen. Plotly unterstützt natürlich auch Theming, so können alle Grafiken automatisch im Corporate Design strahlen.
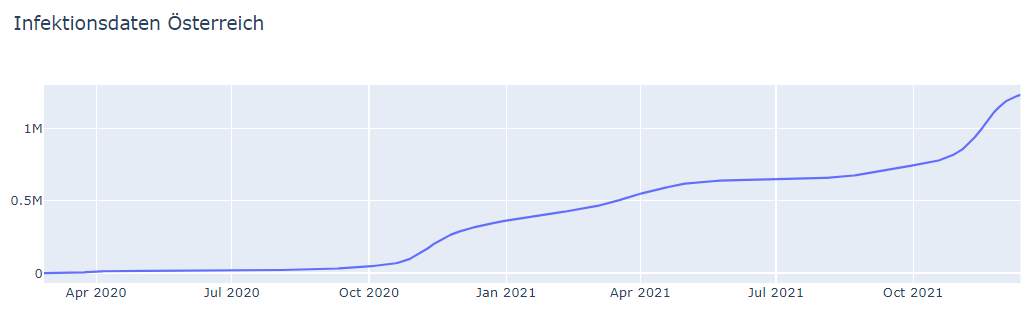
Hier noch eine Visualisierung mit den positiv Getesteten in Österreich, diesmal über die Zeit:
austria_inf_graph = go.Figure(data=go.Scatter(x=austria_df["DATUM"], y=austria_df["ANZ_POS_SUM"], mode="lines", name="Positiv getestet"), layout=dict(title="Infektionsdaten Österreich")) austria_inf_graph.show()
Fügen wir nachträglich noch einen Datensatz zur gleichen Grafik hinzu, die Genesenen.
austria_inf_graph.add_trace(go.Scatter(x=austria_df["DATUM"], y=austria_df["ANZ_GENSN_SUM"], mode="lines", name="Genesen")) austria_inf_graph.show()
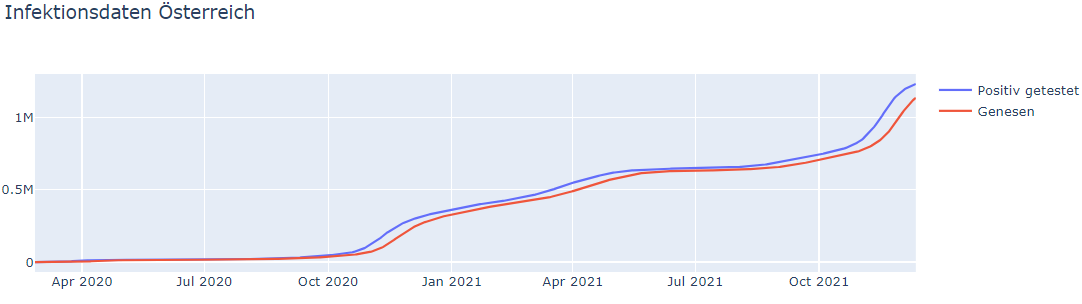
Einfach, oder?
Vorteile
Aufwand
Das Erstellen der plotly Grafik wirkt auf den ersten Blick aufwändig. Wieso sollte man programmieren, wenn man einfach ein paar Daten aus der Datenbank kopieren und manuell eine Grafik erstellen kann?
Die Grafik selbst zu erstellen, vollständig interaktiv und skalierbar, war eigentlich nur eine Zeile Code! Die Datenaufbereitung scheint den Löwenanteil des Aufwandes auszumachen. Diese muss man allerdings nur ein einziges Mal machen. Sie ist darüber hinaus höchst flexibel und leicht zu aktualisieren.
Und war es wirklich so viel? Sehen wir uns den Code nochmal zur Gänze an:
import os
from dotenv import load_dotenv
import pandas as pd
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
load_dotenv(".env")
engine = create_engine(os.getenv("SQLALCHEMY_DATABASE_URI"))
Session = sessionmaker(bind=engine)
session = Session()
austria_df = pd.read_sql_table("Oesterreich", con=session.connection(), schema="dbo")
impfung_demo_df = pd.read_sql_table("ImpfungDemografie", con=session.connection(), schema="dbo")
impf_austria_df = impfung_demo_df[(impfung_demo_df["BL_ID"] == 10) &
(impfung_demo_df["IMPFUNG"] == "BioNTechPfizer") & (impfung_demo_df["DOSIS_NR"] == 3)].copy()
impf_alter_df = impf_austria_df.groupby(["ALTER_GRP"], as_index=False).sum()
alter_bar_graph = go.Figure(data=go.Bar(x=impf_alter_df["ALTER_GRP"],
y=impf_alter_df["IMPF_CUM"]),
layout=dict(xaxis=dict(type="category")))
alter_bar_graph.update_layout(title="Impfungen nach Altersgruppen, ganz Österreich")
austria_inf_graph = go.Figure(data=go.Scatter(x=austria_df["DATUM"],
y=austria_df["ANZ_POS_SUM"],
mode="lines",
name="Positiv getestet"),
layout=dict(title="Infektionsdaten Österreich"))
austria_inf_graph.add_trace(go.Scatter(x=austria_df["DATUM"],
y=austria_df["ANZ_GENSN_SUM"],
mode="lines",
name="Genesen"))
Der Aufwand hält sich in Grenzen.
Skalierbarkeit
Was ist, wenn man nicht eine Grafik braucht sondern eine für jedes Bundesland, dann noch jeweils aufgeteilt nach Altersgruppe/Geschlecht/Dosis/Impfstoff?
Manuell wird das schnell aufwändig. In einer Programmiersprache wie Python sind das ein paar Schleifen. Fertig sind hunderte von Grafiken, bereit zum Export.
Interaktivität und Online-Funktionalität
Plotly ist erweiterbar. Zum Beispiel kann man mit plotly Dash die Grafiken miteinander und mit Steuerelementen kommunizieren lassen und dadurch mächtige online Reportingtools kreieren.
Als Beispiel wäre das hauseigene COVID-19 Dashboard unter https://c19dash.alpha-itc.com zu nennen.
Aber auch einzelne Grafiken kann man einfach als .html exportieren, um sie in eigene Websites einzubinden:
import plotly.io as pio pio.write_html(alter_bar_graph, file="alter_bar_graph.html") pio.write_html(austria_inf_graph, file="austria_inf_graph.html")
Abschließend
Python mit plotly, unterstützt durch pandas und einer optionalen Datenbank, ist eine mächtige Kombination, um komplexe, attraktive und interaktive Grafiken zu generieren, die Sie in Ihren betrieblichen Entscheidungen unterstützen können. Und das skalierbar und so flexibel wie nur eine höhere Programmiersprache sein kann.

