Unterschiede & Einsatzbereiche
In einer datengetriebenen Geschäftswelt wird es für Unternehmen immer wichtiger, Informationen effizient zu speichern, zu analysieren und nutzbar zu machen. Dabei stoßen viele auf zwei Begriffe: Data Lake und Data Warehouse. Aber was ist der Unterschied – und wann setzt man welches System ein?
In diesem Blog-Artikel vergleichen wir beide Ansätze, zeigen die wichtigsten Merkmale und helfen Ihnen bei der Entscheidung, welche Lösung besser zu Ihrem Business passt.
Was ist ein Data Lake?
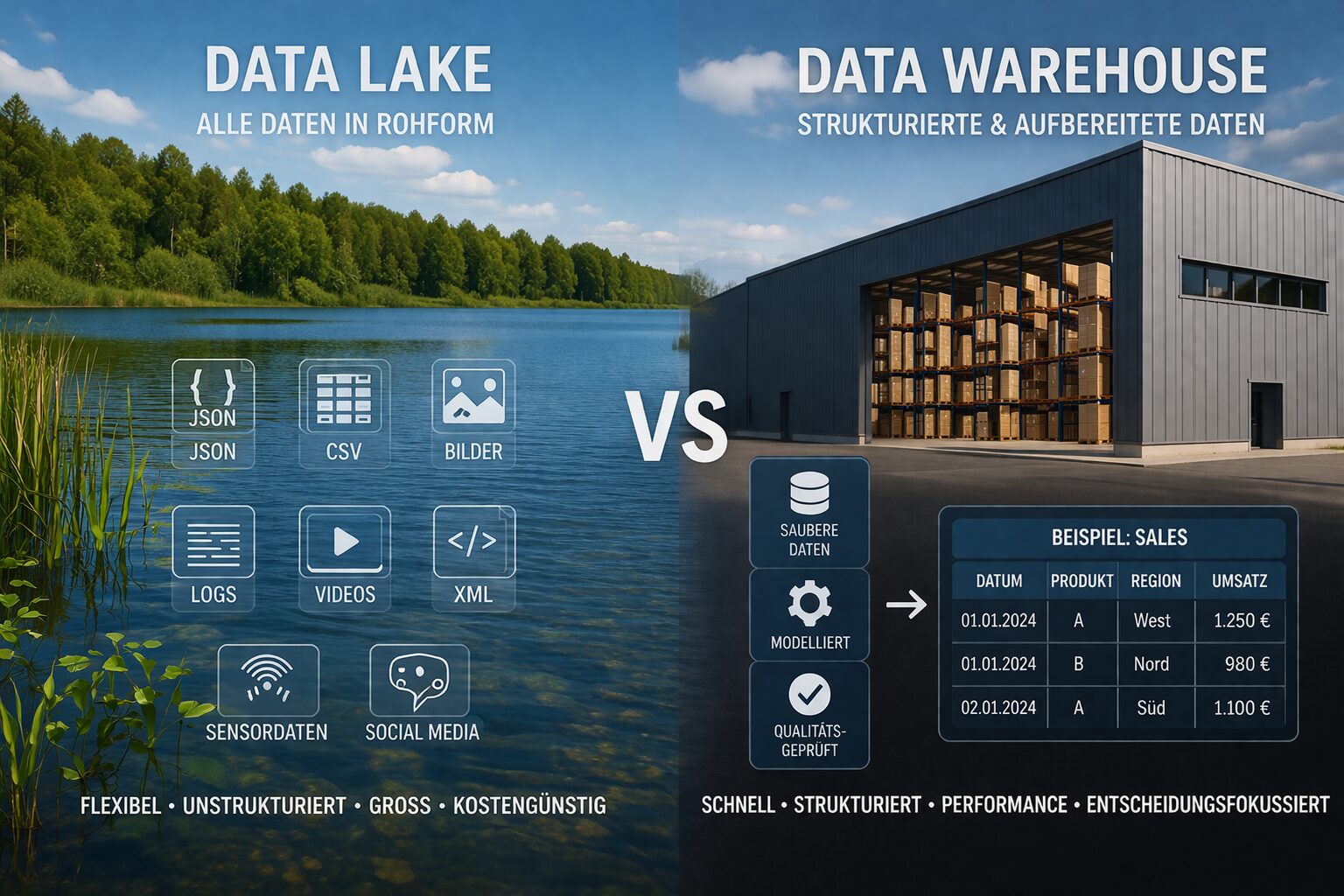
Ein Data Lake ist ein zentrales Speichersystem für große Mengen an Rohdaten – egal ob strukturiert, semi-strukturiert oder unstrukturiert. Beispiele sind:
§ Text- und Logdateien
§ Sensor- oder IoT-Daten
§ Bilder, Videos, Audio-Dateien
§ Rohdaten aus APIs oder externen Quellen
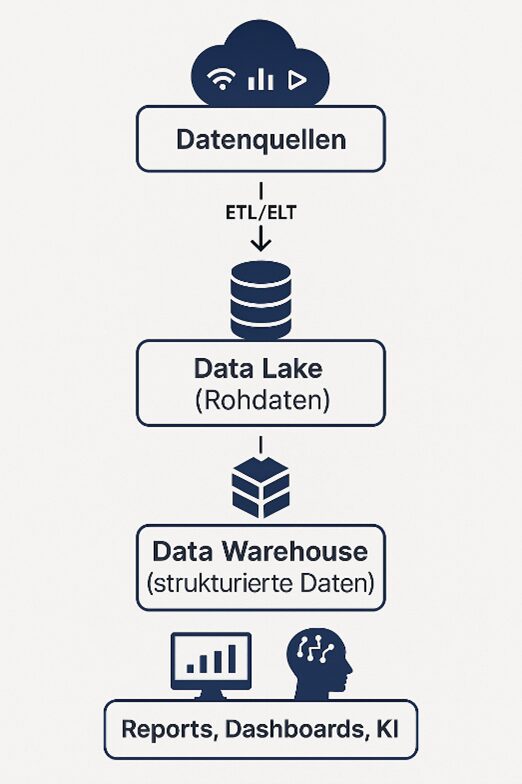
Im Gegensatz zum klassischen Datenbankmodell werden die Daten wie sie anfallen („as-is“) gespeichert. Eine Modellierung oder Strukturierung erfolgt (wenn überhaupt) erst bei der Auswertung (Schema-on-Read).
➡️ Besonders geeignet für Data Scientists, KI-Projekte und explorative Analysen.
Was ist ein Data Warehouse?
Ein Data Warehouse ist ein strukturiertes, leistungsoptimiertes Datensystem für analytische Abfragen und Reports. Hier werden Daten aus unterschiedlichen Quellen gesammelt, bereinigt, transformiert und in ein fest definiertes Schema überführt (Schema-on-Write).
Typisch sind:
- Hochperformante SQL-Abfragen
- Dashboards und Business-Reports
- Daten aus ERP-, CRM- und weiteren Systemen
➡️ Optimal für Business Intelligence, Reporting und datengetriebene Entscheidungen im Management.
Data Lake vs. Data Warehouse – Der direkte Vergleich
| Merkmal | Data Lake | Data Warehouse |
| Datenformat | Rohdaten, unstrukturiert & flexibel | Strukturierte, bereinigte Daten |
| Modellierung | Schema-on-Read | Schema-on-Write |
| Performance | Hoch bei explorativen Analysen | Hoch bei standardisierten Abfragen |
| Kosten | Niedrig bei großen Datenmengen | Höher durch Struktur & Pflege |
| Zielgruppe | Data Scientists, Entwickler | BI-Teams, Manager, Analysten |
| Technologien | Hadoop, Amazon S3, Azure Data Lake | Snowflake, Redshift, Google BigQuery |
Wann eignet sich ein Data Lake?
Ein Data Lake ist sinnvoll, wenn Sie:
- mit unstrukturierten Datenquellen arbeiten
- Daten für Machine Learning oder KI verwenden möchten
- eine kostengünstige Speicherlösung für große Datenmengen suchen
- flexibel und agil mit Daten umgehen möchten (z. B. Prototyping)
Wann ist ein Data Warehouse besser?
Ein Data Warehouse ist die richtige Wahl, wenn:
- Sie standardisierte Reports für das Management brauchen
- Datenqualität und Konsistenz im Fokus stehen
- Geschäftsdaten aus verschiedenen Quellen zusammengeführt werden
Sie schnelle, strukturierte Abfragen benötigen (z. B. mit Power BI oder Tableau)
Fazit: Kombination beider Systeme als Zukunftsmodell
Data Lakes und Data Warehouses verfolgen unterschiedliche Ansätze im Datenmanagement, ergänzen sich jedoch oft in modernen Datenarchitekturen. Während Data Lakes durch ihre Flexibilität und Offenheit beste Voraussetzungen für innovative Analysen schaffen, bieten Data Warehouses Stabilität, Geschwindigkeit und Zuverlässigkeit bei standardisierten Auswertungen.
Moderne Datenstrategien setzen häufig auf eine hybride Lösung:
Der Data Lake dient als flexibler Speicher für alle Rohdaten. Ausgewählte, gereinigte Daten werden anschließend ins Data Warehouse übertragen – ideal für Business Intelligence und operative Auswertungen.
So profitieren Sie von beiden Welten:
- Skalierbarkeit und Flexibilität durch den Data Lake
- Performance und Qualität durch das Data Warehouse